
Welcome to tagtog
This is the official documentation for ![]() tagtog, an efficient text annotation tool ready to train AI. Available on the Cloud and on-Premises. Easy.
tagtog, an efficient text annotation tool ready to train AI. Available on the Cloud and on-Premises. Easy.
Below you can find a brief summary with the main features of tagtog and an overview of what you can achieve using this tool. For more in-depth information or tutorials, use the navigation to the left to explore our documentation.
What can you achieve?
Manual text annotation
Use the text annotation editor to quickly annotate and normalize entities (overlapping annotations supported), add entity labels, relations and more. If you just need to annotate at document level, you can use labels to tag documents. The user interface adapts automatically so you only see what you need. No more complex or non-intuitive annotating systems/interfaces, engage your domain experts from the very beginning.
Too much work for a single person? Invite others and work in group. Each annotator can annotate the same text to facilitate the review process and to meet quality requirements. Once the annotations are completed, you can adjudicate, and export them to JSON format.
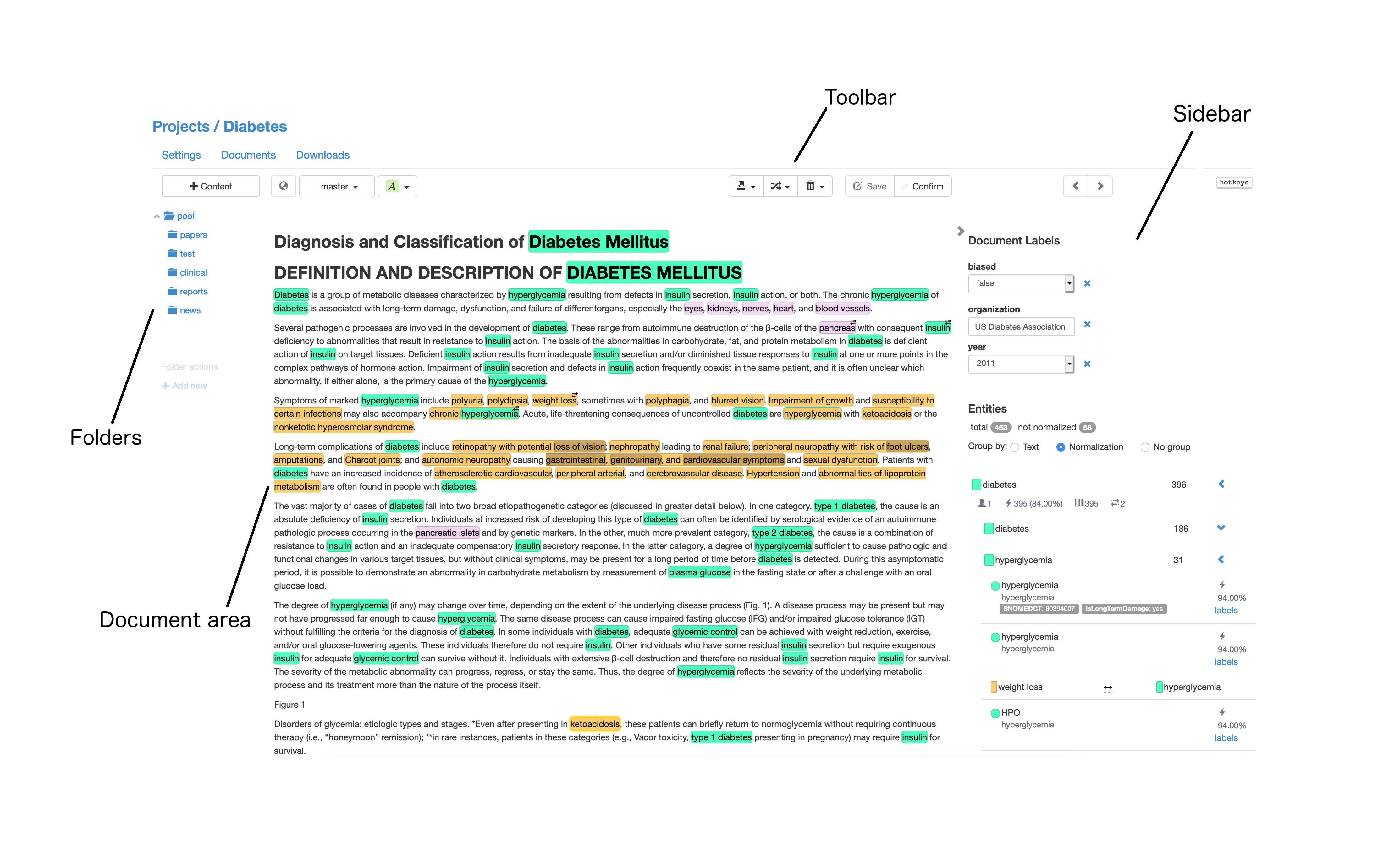
Editor layout. In this examples there are entities, entity labels, document labels, relations and normalizations
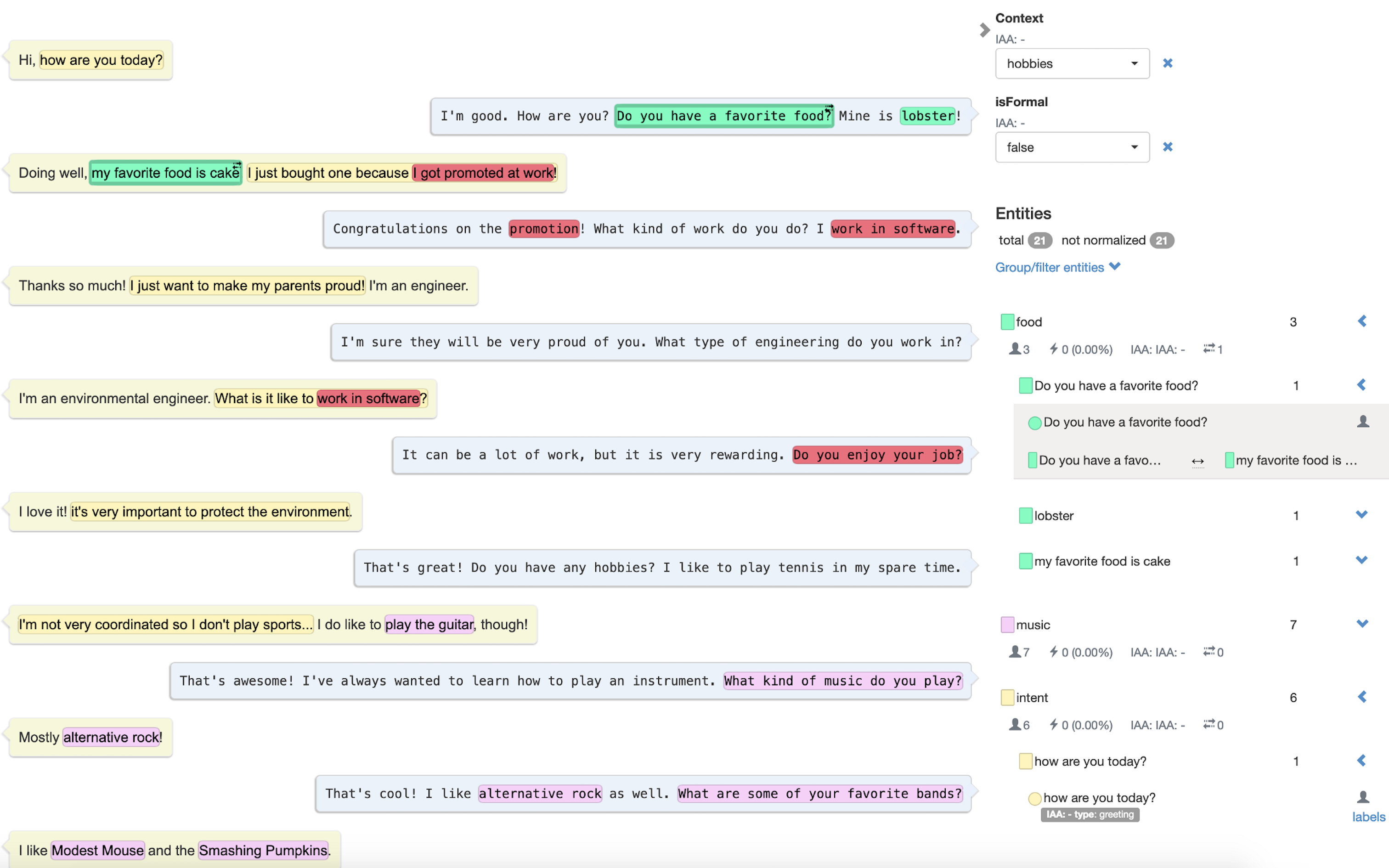
Building your custom annotation layout. Example of a conversation between a human and Facebook BlenderBot chatbot
Do you need to deal with PDFs? ![]() Use the PDF Annotation tool to annotate native PDFs within tagtog.
Use the PDF Annotation tool to annotate native PDFs within tagtog.
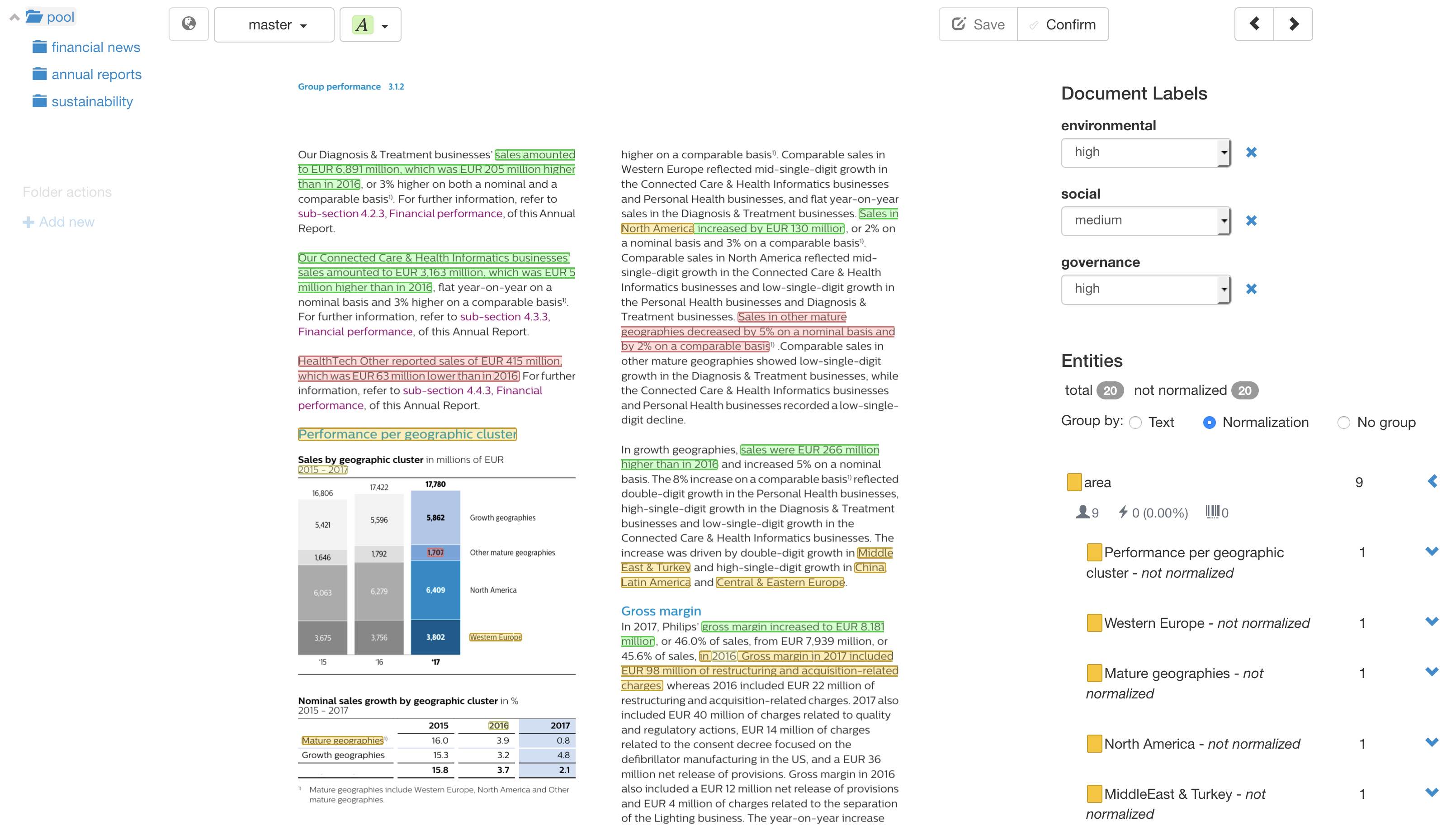
Annotate PDF natively, as they are and the way your team is used to work with them
Automatic text annotation
Not fast enough? Use automatic annotations to speed up annotator tasks. Use pre-selections, dictionaries, tagtog ML or plug your own ML model in. Users will see the automatic annotations and just make an action when predictions are wrong. Powered by NLP algorithms, tagtog uses the corrections to improve accuracy and continuously reduce the load of annotators' work.

Train your own AI
With tagtog you can quickly create training data to feed your AI models.
1Use tagtog to annotate text and create training data. This is a collaborative tool, so you can invite others to share the effort. Augment your data: label documents, annotate text, relations, etc. Export this data to your model to train it.
2Import the new model's predictions to tagtog and use the annotation editor to correct any wrong prediction. The user interface is built to minimize annotator's effort while maximizing the input for your model. Once done, export the new training data to your model.
3Repeat the last step until you have tuned your model.

Get relevant insights from text automatically
Insights are just meta information (annotations) on the top of the text analyzed. You can either use dictionaries, tagtog ML, or plug your custom model in to automatically generate this meta-information. Just annotate, you don’t need to code, deal with complex installations or juggle with data.
1Provide tagtog with as many initial examples as possible. Bootstrap a model with pre-annotated data or dictionaries with the terminology you would like to identify automatically. If you don't have these resources, no worries. Just start from scratch.
2Train a model: import text (cloud or on-premises) through the API or the user interface. The text is annotated automatically. You can distribute the work across your team and they simply need to correct the wrong model predictions in the annotation editor and confirm the corrections. With each confirmation your model learns. Repeat this step until you get the accuracy level required.
3Congratulations! You get a machine learning model ready for production use. Simply send text (or documents) to the API or user interface to retrieve relevant insights. If you detect any problem with the results, you can always continue annotating to fine tune the model.

Index your data
Train tagtog ML or your own model to annotate automatically your data. These annotations will be the meta-information used to index your data. This data augmentation improves the discoverability and it is key to make search quicker and more intuitive.
1Train a machine learning model as described in the previous use case.
2Send your text items to tagtog using the API. Get the annotations in JSON format and decide whether to store these in your own system or keep them at tagtog. Your data is indexed.
3If you keep these annotations at tagtog, you can use the concept search via API as your search engine. Otherwise, you can store this data locally as meta-information for your own search engine.

The annotation editor
tagtog comes with an advanced text annotation tool for data augmentation. Its design is based on the feedback from annotation groups.
Focus is key in order to generate a high-quality annotated corpora, and we know this. Each single mistake in the annotations means a step backward and more effort to achieve the desired results. With this in mind and to make the user feel comfortable while reading, we have created a minimalist user interface where the text is presented with natural spacing, same as any user can be familiar with. By protecting the reading experience the tool is more accessible. This is specially important when you involve subject matter experts in your annotation projects.
Usually annotation tasks involve dealing with big volumes of texts. Speed and efficiency are essential to minimize costs and time. tagtog includes features as automatic annotations, overlapping text annotations or full-text annotation, that reduce significantly the time required to annotate text.
Do you need to annotate or process PDFs? Use the PDF annotation tool, it is fully integrated with tagtog web interface.
With the annotation editor you can add different types of annotations:
| Annotation type | Description |
|---|---|
| Entity | Span of text representing a named entity. It can be any span: a part of a word, a word, a sentence or a group of words. Each entity belong to one or more entity classes (e.g. Obama is a person and a politic). |
| Normalization | Id assigned to a named entity. These annotations help in disambiguation. For example an air filter in automotive can make reference to cabin air filter or engine air filter. With tagtog you can assign the correct reference to the entity. |
| Entity label | Attribute (boolean, string, enum) assigned to a named entity. Let's say you are extracting technical issues from reports in a CRM. When annotating those reports, you can add extra information to those entities (technical issues), for example, the severity for each of them. Entity labels can be used with specific entity groups (e.g. only can be set for technical issues) or to all entities (e.g. we can set comments for all entities) |
| Relation | Relation between two named entities. Each relation belong to one specific relation type (e.g. geneBRCA2 is_located on the chromosome 13 location). |
| Document label | Label (boolean, string, enum) assigned to a document or text. These annotations help in text or intent classification. For example, if you are classifying emails in order to dispatch them to different departments, you can create a document label (enum) and classify emails as, for example, sales, technical support or legal. |
Build powerful annotation layouts with tagtog blocks
tagtog supports a wide variety of input formats. In addition, you can create custom styles/layouts to build more attractive content and keep your team engaged.
Using tagtog blocks you can add multi-column layouts, tweets, human-bot conversations, quotes, annotation tasks, etc. There are add-ons available to further customize annotation blocks. For example, you can mark a block with a warning to indicate the annotator should focus on that piece.

Two-column layout for a translation task. The text to translate is on the left column, the text translated is on the right column. The translation in the second row was marked with the attention add-on to warn the user of a potential issue with this translation.
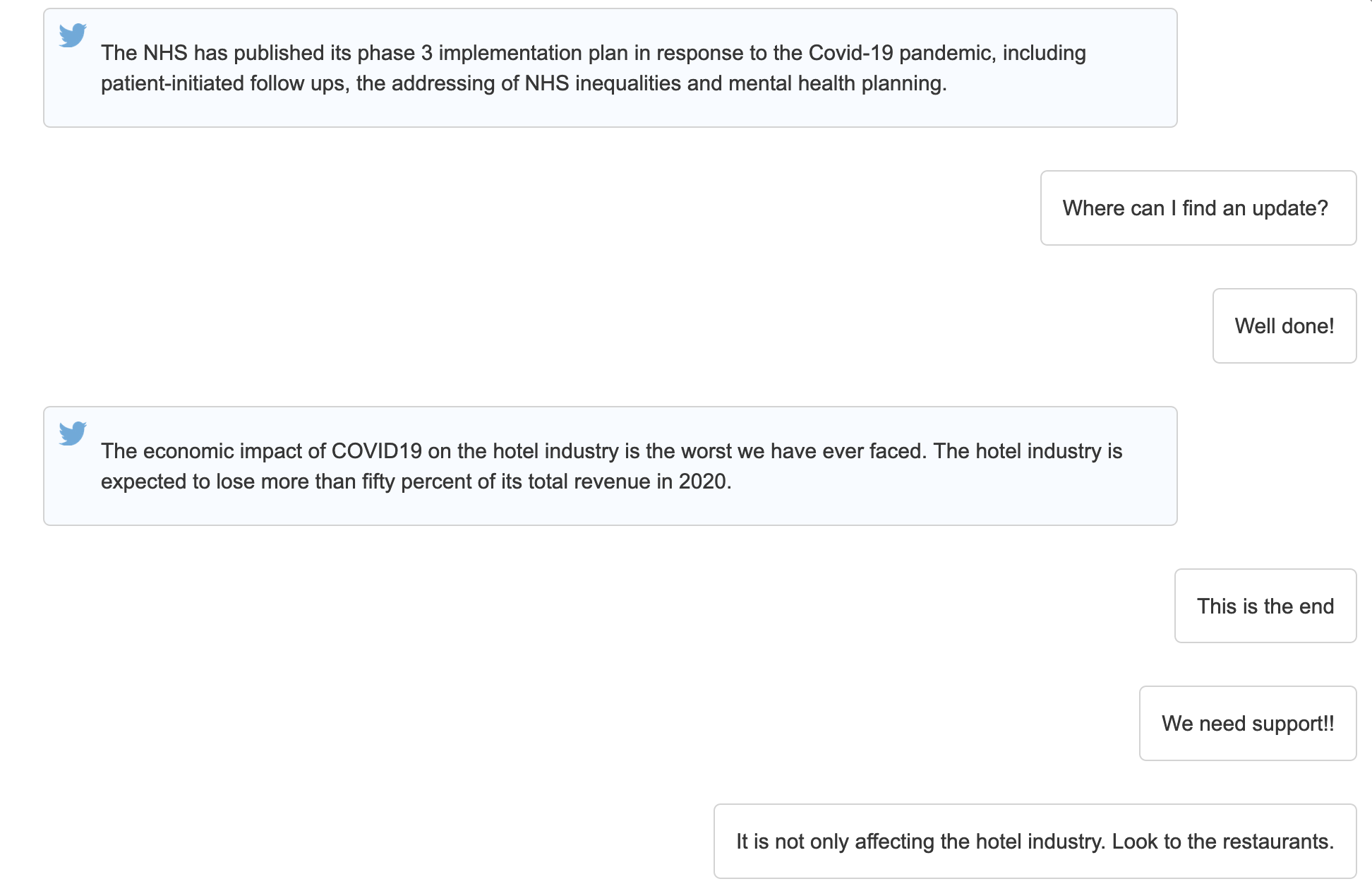
Tweets on the left, comments for those tweets on the right
Team collaboration
Guidelines: define your annotation guidelines within the application and invite others to join your project.
Versions: each annotator has their own version of each document. Therefore, the same document can be annotated by one or more member. Your team can annotate directly on master (ground truth) or on their own versions.
Roles: you can assign different roles to your team members to perform common tasks in an annotation project: admin, annotator, reviewer, reader, etc. There is a pool of about 30 different permissions to define custom roles.
Teams: you can create teams (user groups) and add members to it for easier user management. Invite a team to a project, edit team members, etc.
Track Quality: use the Inter-Annotation Agreement (IAA) for each annotation task, check how well your team agrees on, for example, annotating drug names, law provisions or risk attributes. These values help you understand the quality of your data.
Adjudication: if many users annotate the same document for quality purposes, eventually it needs to be decided, which version (or combination) to adjudicate to master. In tagtog, you can adjudicate a specific version or merge the different versions automatically applying different strategies (e.g. by IAA, majority vote, intersection, union, etc.)
Review: validate or correct the members' annotations. Merge them together and resolve conflicts.
Automatic task distribution: distribute documents automatically to all annotators or to a subset.
Track progress: follow your project progress, bias metrics and the progress of each member.
Train AI as a team: it is easier than ever to collaborate and to train machine learning models together. Using Webhooks you can plug in your custom ML model to train it through tagtog's user interface. Load your model predictions into tagtog and let your team correct them. Each time a document is confirmed, your model will receive the corrected annotations to train itself. Repeat the process until you get the desired accuracy.
Cloud or OnPremises
| On the Cloud. To use tagtog on the cloud, you don't need to install anything; just sign up, create a project, and start annotating. Out of these annotations you can create and use a machine learning model without worrying about hardware requirements, databases, scalability, deployments and any other hassle or cost related to setting up a production environment and maintaining it. |

|
|
OnPremises. If you need to meet strong privacy regulations, legal requirements, or you simply want to make a custom installation within your infrastructure or any public cloud (AWS, Google, Azure, etc) , tagtog is also served on-premises. This is a self-contained version (no Internet connection is required) of tagtog, no data will leave your infrastructure. To make the installation the easiest possible we offer tagtog contained in a Docker image. Check our on-premises guide. There is available support for Single Sign-on and advanced user management (user groups, roles and permissions). All through an intuitive sysadmin panel. |

|
Concept search
Each fragment of text annotated or processed using tagtog is indexed within your project. The search engine makes easier to discover patterns or find actionable insights through search queries. This is specially handy when you have trained a model that annotates automatically relevant information. For example, if you have trained a model that has extracted skills in thousands of CVs, those got indexed and you can search across them using normalizations, entity classes, etc. You can do things like: entity:softskill:time-management to retrieve all CVs from people who are good organizing their work time.
This search engine can be used through the user interface or the API. You can use directly the API as your search interface or simply augment your existing engine.
Annotators can use it to find texts that are not annotated yet or documents related to their specific annotation task.
Import text from known sources
When you need training data, bring real content directly from the source with no effort. tagtog supports shortcuts and automation for these resources:

|
PubMed is the largest and the most widely used database of life sciences and biomedical literature. It contains more than 26 million scientific or clinical articles going back to 1966. |

|
PubMed Central (PMC) is a full-text archive of biomedical and life sciences journal literature with more than 4.7 million articles. |
Check all the input/output formats available.
Open Datasets
Visualize, check quality and download Open datasets from the community.
Extend existing open datasets with your custom data.
Combine the data with the same info type from different data sources (e.g. sentiment labels from product review datasets). Make your data grow easily.
Invite other users to help you annotate your data.
Use existing open datasets, and build a machine learning model that generates similar annotations automatically.
It's free!
| Go to dataset full list |