
Two of the main barriers to Machine Learning are deployment and scaling. Deploying manually models requires time and engineering resources. Scaling the usage of these models requires a powerful infrastructure, the effort to maintain it and cost control. With tagtog, this complexity is transparent to users. We take care of the training mechanisms, the deployment and the handling of usage spikes. You only focus on problem solving using the web editor to indicate what you want to recognize in text. This will be the training data tagtog learns from. All without writing any code, empowering experts in any field to train and use machine learning models.

One of the advantages of using tagtog ML is the possibility of annotating text automatically using machine learning (ML) ![]() Why is this important? Automatic annotations are just insights on the top of the text. You can leverage intelligence in different scenarios:
Why is this important? Automatic annotations are just insights on the top of the text. You can leverage intelligence in different scenarios:
tagtog annotates text automatically using custom or pre-trained ML models. This means you can automate processes to find relevant insights automatically. E.g. analyze customer feedback on real time.
Automatic annotations can boost annotator performance. Documents are pre-annotated by ML models and annotators only need to correct wrong predictions. tagtog learns from feedback and provide with more accurate results with each iteration.
Index your data. Use automatic annotations to augment your data and improve discoverability (e.g. augment records with mutation mentions using standard names, easier to find). You can either import the results into your own system or use the Search API to find suitable records across the data imported.
How does it work?
In tagtog, training data means annotations in any of supported types. You annotate, you train ![]() tagtog is implemented using semi-supervised learning algorithms that reduce the volume of training data required. One of the strongest points is the ability of models to learn continuously and adaptively to incrementally take into account different scenarios but still being able to re-use and retain useful knowledge and skills during time.
tagtog is implemented using semi-supervised learning algorithms that reduce the volume of training data required. One of the strongest points is the ability of models to learn continuously and adaptively to incrementally take into account different scenarios but still being able to re-use and retain useful knowledge and skills during time.

Training flow
To train a ML model follow the next steps:
1Create a project and activate Machine Learning (Settings > Annotations).
2Define one or more entity types.
3Import a document (if you have pre-annotated documents you can import them too) and annotate the text with the entities you want to extract automatically. When you have finished annotating, use the Confirm button to tell tagtog these annotations are ready to be used as training data. When you click this button, in the background, the custom model is being trained and deployed automatically using all the confirmed annotations in your project. The process is very fast and you can immediately annotate other documents automatically using this model.
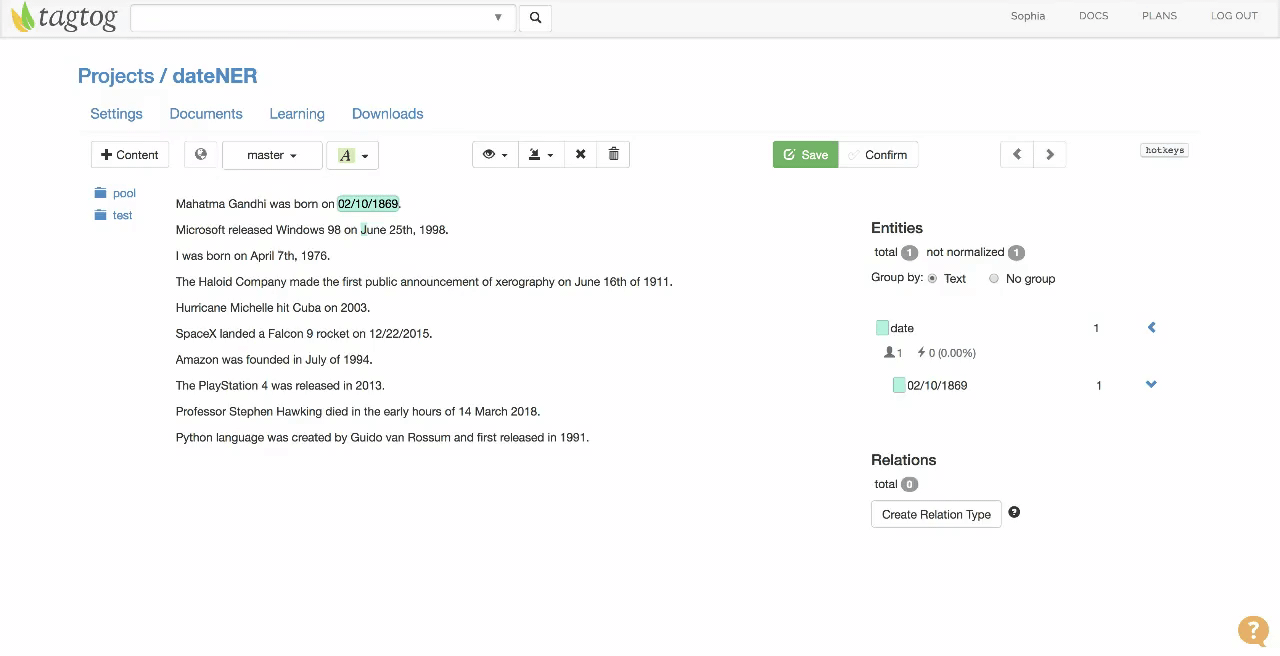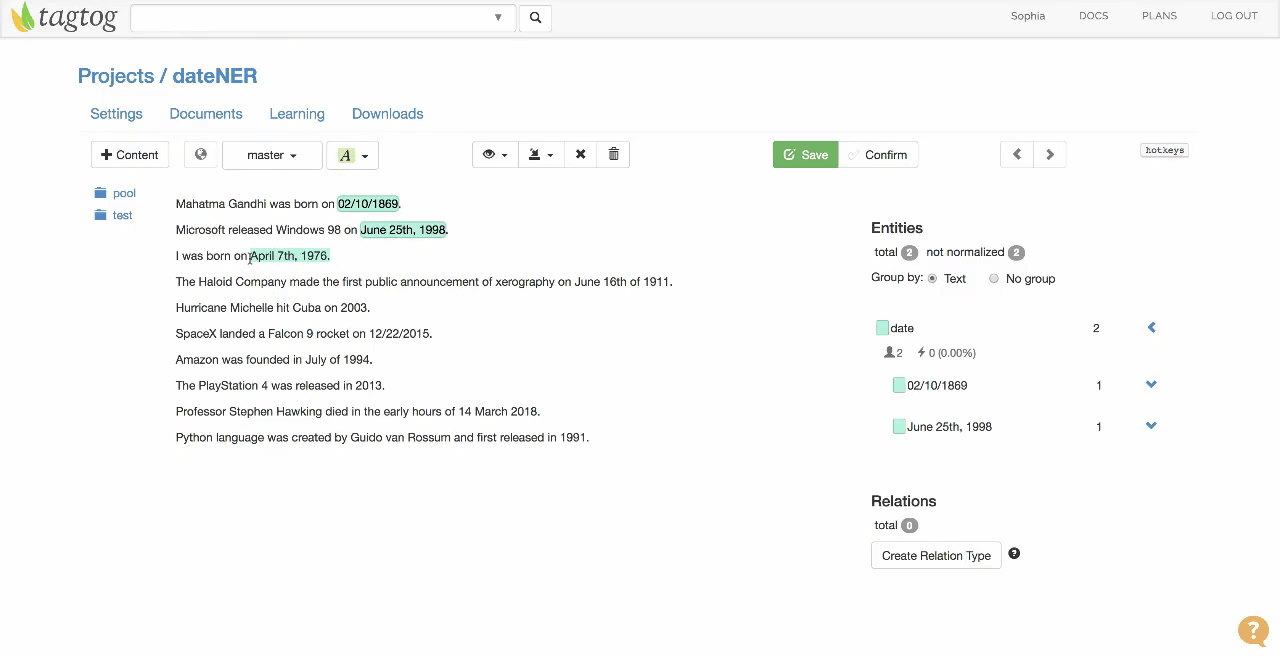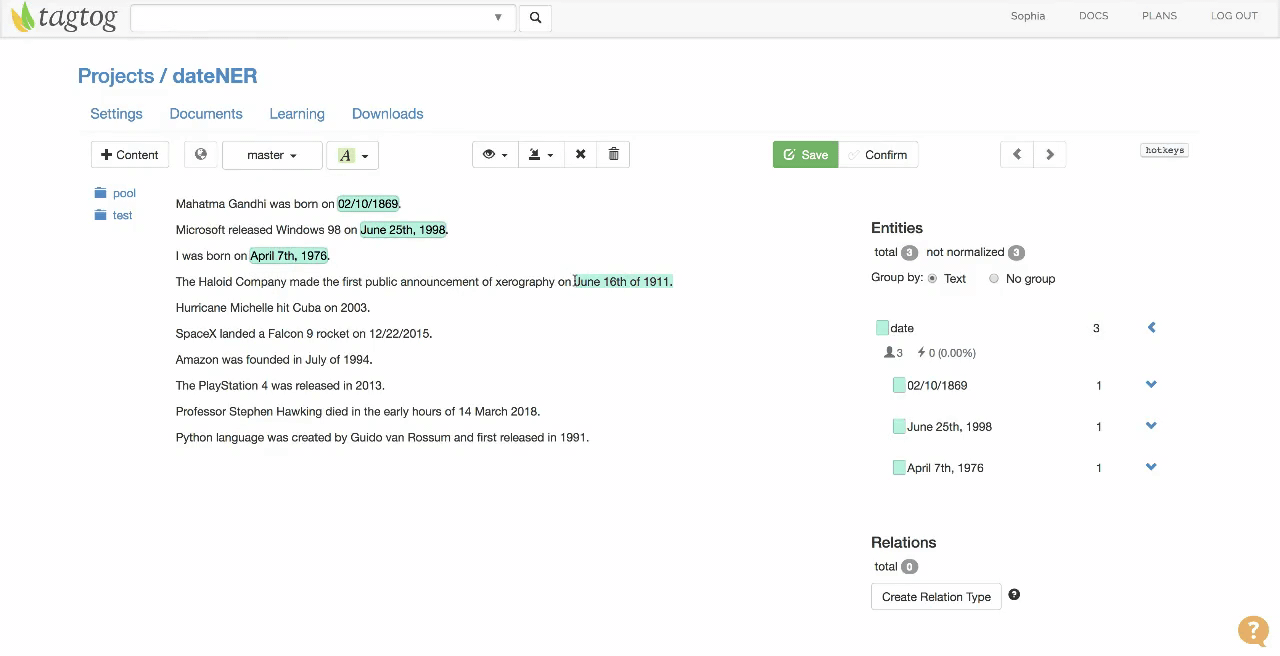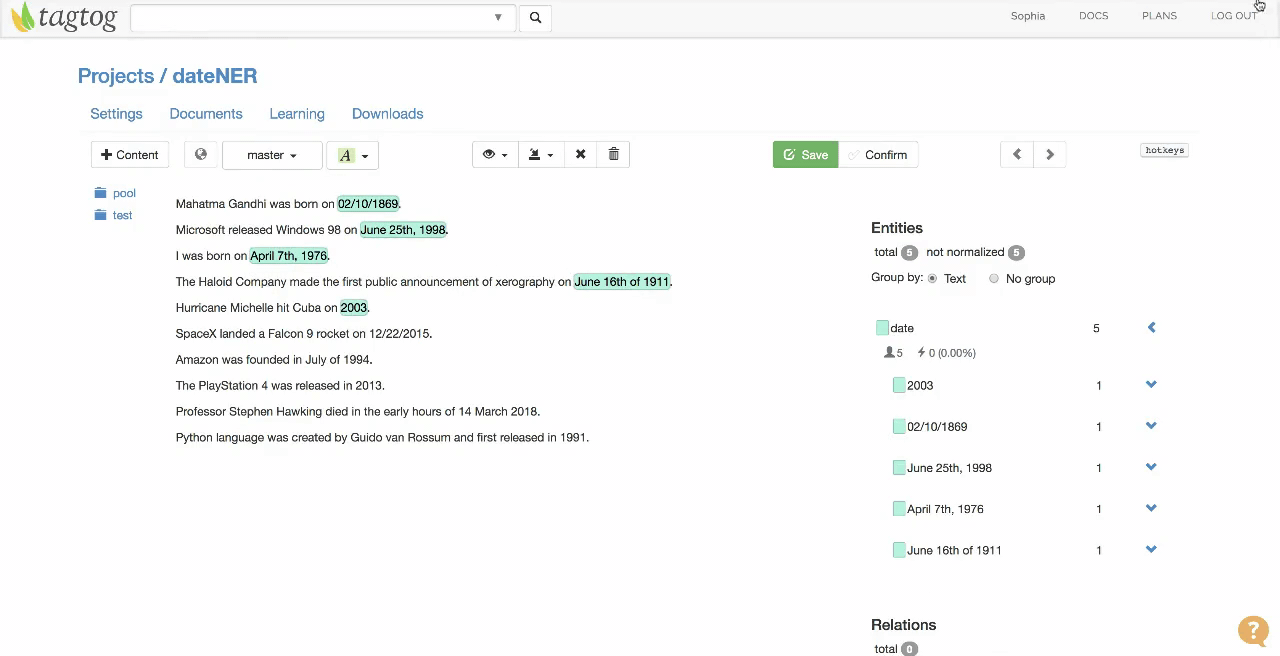
Example of document where dates are being annotated
4Use the model. When you import new documents using the interface or the API, they are automatically annotated by the custom ML model.
5Continuous learning. Were any automatic annotations wrong? was important information not annotated? something new to teach? No problem. Just remove/edit the wrong annotations and add those that are missing. Click on the Confirm button. Again all the confirmed documents are used to retrain the model with your new findings.
Follow this hands-on quick tutorial to understand how easily you can train custom models.
Continuous learning
tagtog smoothly update your custom prediction models with the changes in your annotations. Each time you confirm the annotations of one of your documents, the model is trained with all your confirmed documents used as training data. There are two ways you can retrain your model iteratively:
On top of previously learned knowledge. You just need to import new documents, edit the wrong predicted annotations or add new ones and click on Confirm. Your model has been retrained using this new knowledge.
Changing historical data. Yes! this is possible. Your documents are indexed within your project. You just need to go to the document you want modify (even if it was used previously for training), toggle the Confirm button to allow the changes and make the required changes. Once finished, click the Confirm button again and voilà, your model is trained and deployed including these changes. Usually you want to perform similar changes across the documents of your project, use the search engine to find the documents to modify.
tagtog ML annotations and dictionary annotations
Machine learning and dictionary annotations are annotated automatically. They can work independently or combined.
When a ML model is trained, it uses the data from your dictionaries as a feature.
Currently, the normalization of entities can be only done with dictionaries. ML annotates entities, but it doesn't normalize them. If you combine both mechanisms ML will annotate and dictionaries will normalize.
tagtog ML limitations
tagtog ML is designed and optimized for:
NER. Annotations with a small amount of tokens. It is not optimized for sentence or paragraph annotations.
Small number of entity types. Internally, each entity type generates a separated and independent model.