
Introduction
The Portable Document Format, or PDF is one of the most popular file formats. PDFs are everywhere.
PDF has become a de facto global standard for more secure and dependable information exchange since Adobe published the complete PDF specification in 1993. Both government and private industry have come to rely on PDF for the volumes of electronic records that need to be more securely and reliably shared, managed, and in some cases preserved for generations.
— An excerpt from the ISO 32000-1 standard
As you can imagine, if you work with text, sooner or later you will need to deal with PDFs. However, it's still a format that causes headaches for people trying to add or extract knowledge to/from them. That's why we have built a PDF annotation tool integrated within tagtog. Our goal is to facilitate the processing of PDFs for entity/relations extraction, document classification,manual annotation and other tasks.
How to activate this feature?
By default this feature is turned off. You can change this setting differently for each project. To activate this feature follow these instructions.
How does it look?
It is the same web interface as in tagtog, but annotating directly over the native PDF ![]()
You can annotate any text in the PDF: captions, text in images, figures, tables, etc. Just make sure the text is not an image itself.
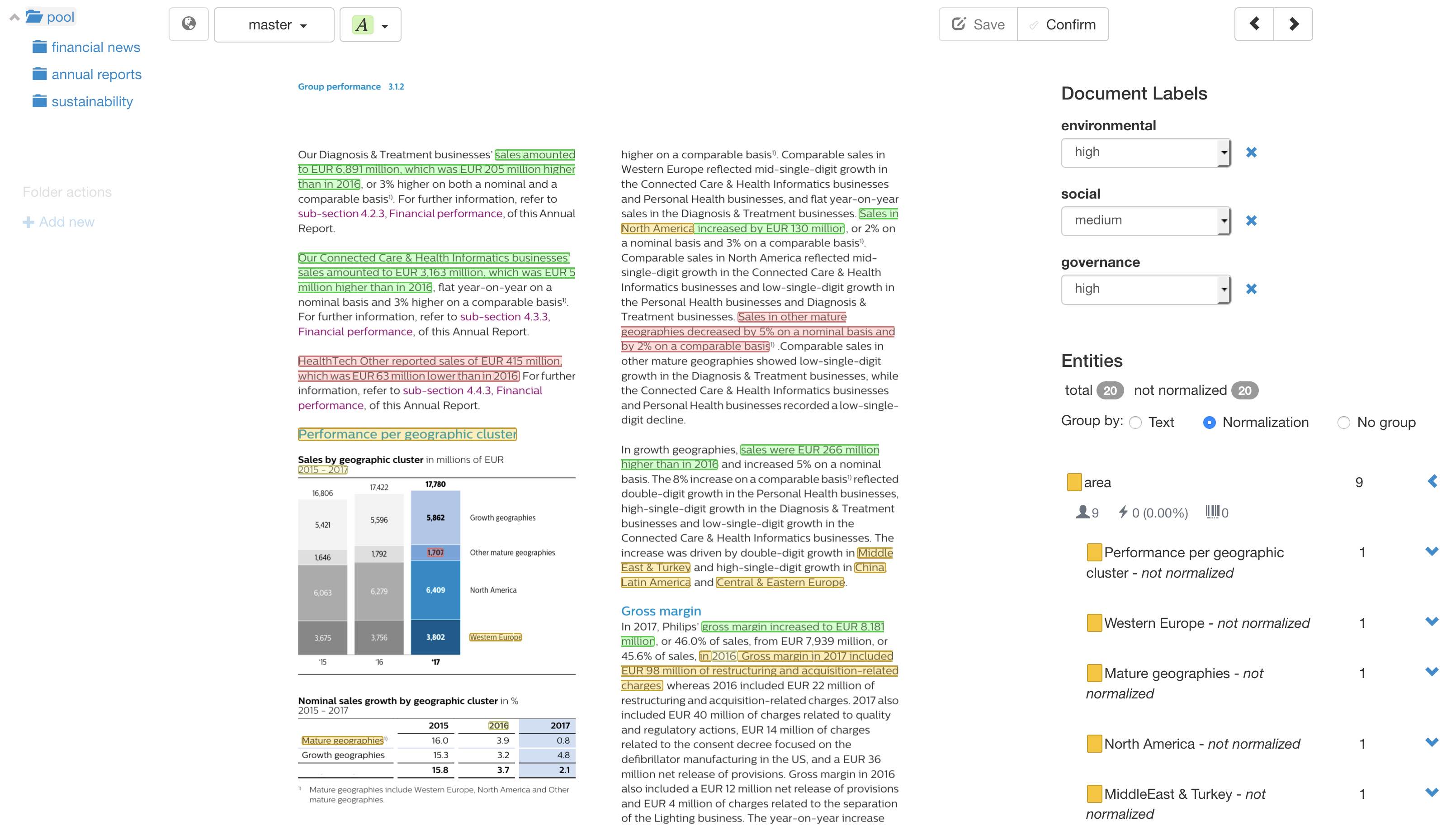
Annotate titles, figures, tables, forms, etc.

Beautiful and engaging for annotators
Document navigation
You can navigate by just scrolling with your mouse or clicking on the arrows on the toolbar.  If you want to go to a specific page, just write the page number in the page text box and press enter ↵. The page navigation will float when you scroll down a document to allow you change the page at any moment.
If you want to go to a specific page, just write the page number in the page text box and press enter ↵. The page navigation will float when you scroll down a document to allow you change the page at any moment.
Zoom
Zoom in & out the document  . The scale changes in 25% intervals.
. The scale changes in 25% intervals.
Pan
Also known as the hand tool. You just click in an area where there is no text, this cursor shows up ![]() . Drag the document horizontally or/and vertically and release the mouse button to stop panning.
. Drag the document horizontally or/and vertically and release the mouse button to stop panning.
Search
In paginated documents as PDF, you can find text across a particular document. Use the keyboard hotkeys ctrl+f or command+f to trigger the text search functionality.
Once you start typing, the search functionality is triggered and the results are updated in real time and highlighted in the screen, e.g.:  . In the text search panel you can navigate across the results by clicking the up and down arrows. Results are displayed in order of appearance. When you navigate to one particular search result, it is being highlighted, e.g.:
. In the text search panel you can navigate across the results by clicking the up and down arrows. Results are displayed in order of appearance. When you navigate to one particular search result, it is being highlighted, e.g.:  .
.
To clear the results, just close the text search panel.

Text search panel. You can navigate across the results. The number of results is displayed inside the text box
Annotations
tagtog uses two different measures to locate annotations done over native PDFs. Both are contained in each annotation:
Text offsets. Each annotation is located using the start offset of its text in reference to the beginning of the page containing the annotation. In order to do that, we transform each page of the PDF into text and save the result in the plain.html format. We use this file as a reference to calculate the offset of the annotations. You can download and use this file to share a common interface with tagtog. Offsets take into account the reading order of elements such as tables or columns.
Coordinates. Each annotation is located using the coordinates of the bounding box containing the annotation. Currently, each annotation uses a pair of coordinates (X, Y) corresponding to the top-left of the first character of the annotation and the bottom-right of the last character of the annotation. In order to facilitate translation, coordinates are expressed in Points(pt). 1pt is equal to exactly 1/72th of an inch. The coordinates system has its 0,0 position in the top left of each page.
Following the syntax from other text input types, the page number is encoded in the partId field for each text annotation. For example: s6v1 refer to page 6, s20v1 refers to page 20 and so forth.
Pre-selections are available in the PDF annotation tool. For example, when a user annotates a text, if there are other occurrences of the same text in the document, these are also annotated. Please notice that the annotation coordinates are not attached to the newly created pre-selections. tagtog attaches the coordinates only when the user confirms the pre-selection.
Spacing
To help your NLP pipeline, this is how tagtog organizes end of lines:
Single space. When a new line is close enough to the previous one, a single space is added by tagtog. This is specially useful for multi-column documents.
End of line. When tagtog identifies a change of section or discourse unit, two newline characters are added (\n\n).
How does it help you?
Processing PDF files is a painful process full of tears. To solve this, we have built a PDF annotation tool. This is how it can help you:
Annotate over the PDF. Annotate directly over the native PDF layout. PDF files contain figures, pictures, tables, etc. Stripping only the text, you destroy part of the original context reducing the global understanding of the document.
Train your own models easily. Annotate native PDFs; then use them to train your ML models as easily as if they were plain texts! ![]() Find below how and forget about processing PDFs yourself.
Find below how and forget about processing PDFs yourself.
Fully integrated. The PDF annotation tool is a web component fully integrated with tagtog. Annotate relations, document labels, entity labels, etc.
Annotate any text Sometimes image captions are important, text in tables is critical, etc. Don't miss this important source of knowledge, now you can annotate these and any other text that you find in the PDF.
Training your model to process PDF files
1Annotate using the PDF annotation tool. Import a PDF and annotate it using the native layout.
2Download the plain html (text content) and annotations. Use the API or user interface to download both: the ann.json with the annotations and the plain.html with the text content. The offsets from the annotations refer to the plain html.
3Train your model. Use the annotations and the plain html to train your model.
4Import new PDFs with the annotations from your model. Import the PDFs to tagtog and download the plain htmls using the API or user interface, use this easy to digest text as an input for your model. Now push the resulting annotations to tagtog. You can automate this process using Webhooks, so each time a PDF is imported, you get automatically the plain.html file, the annotations are generated right away and pushed to tagtog. Here is a fully-functional sample GitHub repository.
5Continuosly train your model. Annotators review the annotations from your model over the native PDF layout and correct them. You can use the new ann.json files to update your model and increase the accuracy of your predictions over time. More information.
Caveats
You cannot create an annotation with one piece in one page and the other piece in the next page. The main constraint is that the PDF footer interferes when creating an annotation across two pages.
If you double click in a word, no annotation will be created. Currently, this feature is only available in the plain text editor.
Warning: please make sure your browser extensions are not conflicting with the viewer. This might have an impact on the viewer’s performance.